
Keyword research tools help content creators understand what their audience is searching for. But where does that data come from, and what does it mean?
If you receive a list of target keywords or a keyword research spreadsheet, do you know how they were sourced? Where exactly does your keyword data come from? Your answer is likely "from my browser extension," "from our audience editorial team," "from my keyword research tool" or "from our digital marketing agency."
Now that digital marketing has become common, if not sophisticated, many basic aspects of the optimization projects are taken for granted or considered "magic." You get the keywords from the keyword generator because your online SEO course or your boss explained that's where to find them. You use the software, organize the keywords, and pass off to the next person.
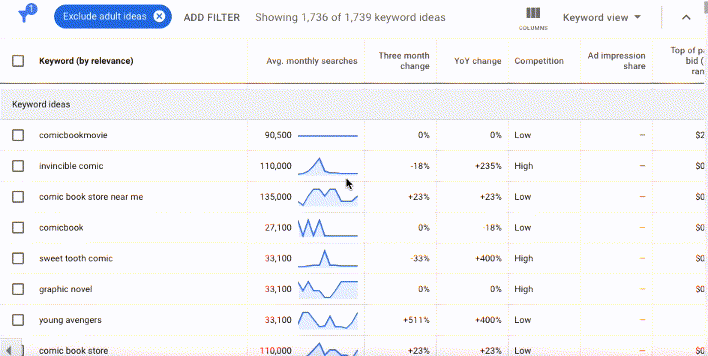
You may even understand how some variations of your keywords got there: if you entered the word "comic books" into a keyword research tool, you shouldn't be surprised to see search terms like "comic book store near me," "marvel comic books" or even "graphic novel," the more literary synonym for comic books.
But why are you seeing terms like "seduction of the innocent," "orc stain"or "tokyo ghost" in your research report when the seed term is "comic book"?
The answer lies in how Google's search algorithms process, analyze and process textual data from both advertisers and search users, creating what semantic analysts call knowledge graphs and entities.
 Deborah Carver
Deborah Carver
Google's decades-long data harvest
A note: Researching Google via Google is a bit of an ouroboros, since Google does its best to keep only its most current policies and best practices on its website and its search results. Please know that this newsletter is an overview from an experienced professional on a deadline, and from not a historian. I acknowledge that a more journalistic documentation should use a tool other than Google... like a library or a book or an interview with an expert. I gave other search engines the ol' college try with little luck. Like much of 2000s era digital history, the history of keyword planner or any of the platform's core advertising technologies would be a great thesis topic.
Since the Google search engine launched in 1998, it's collected and stored the search terms that it uses in a database. In 2000, Google launched its search ads, followed by a self-service ad administration tool. With the self-service tool, advertisers could name the keywords they wanted their ads to appear next to, so if they were selling shoes, they could bid on "shoes."
To help advertisers find the most relevant keywords for their products—and likely to encourage the use of keyword-oriented thinking in general—Google launched Keyword planner. Again, more historical data needed here, but for as long as I've been working in search, keyword planner spits out recommended search queries and phrases based on a seed query, website or landing page.
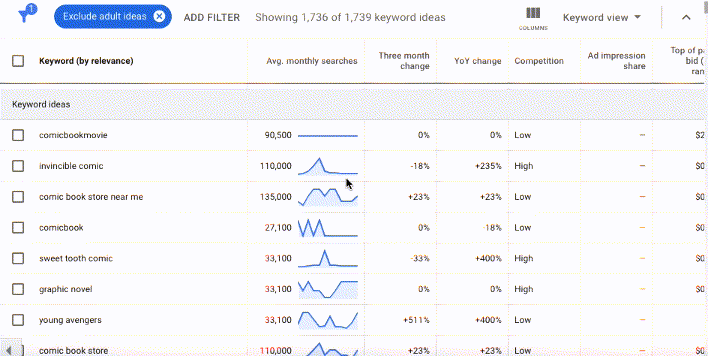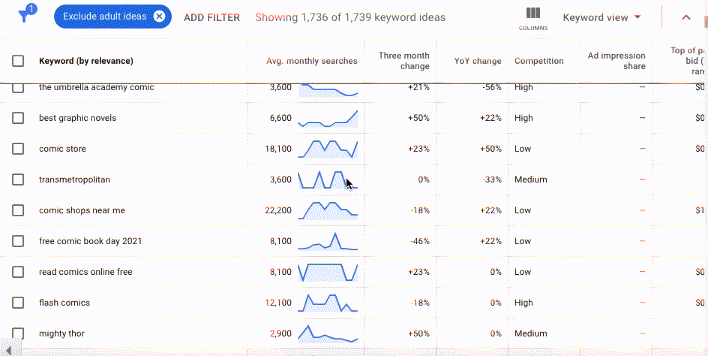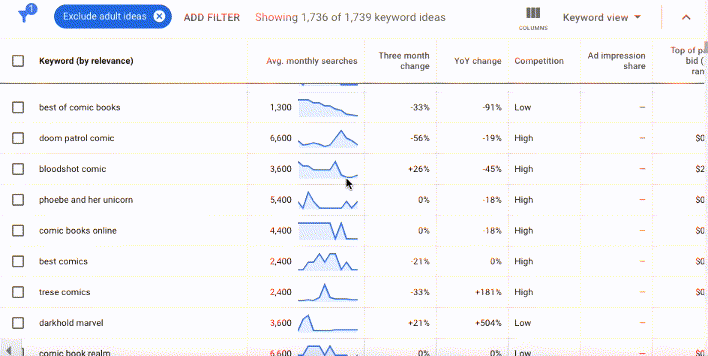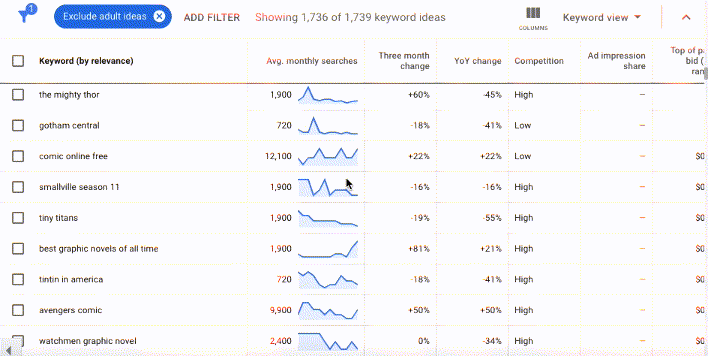
In Google's nascent years, Keyword Planner data was freely available to all Google Ads users, no matter how much they spent on ad buys. But to "protect user privacy" and business interests, Google significantly scaled back what's available in keyword planner for free.
Since 2016 organic researchers like me have needed to either piggy back on a well-funded paid Google Ads account or subscribe to a keyword research tool to have access to more detailed keyword research data. The free version of the data in the gif above is deeply stripped back. In the free version, researchers can see the keywords, but the search volumes and forecasts are obscured into ranges in multiples of ten.
Deborah Carver
Where does Keyword Planner and Google Ads API data come from?
Master advanced keyword research techniques.
Take the More than (key)Words course.When you use Keyword Planner or a keyword research tool for the first, third, or three-hundredth time, it can feel magic. How does Google know that all those words, many of which I've never even thought about before, are related to my original seed query?
Google Ads keyword planner data is compiled from two decades of the following:
- Billions of end users who type queries into the platform to search for literally anything on the internet, ad nauseam, every day
- Advertisers providing lists of keywords so they can buy relevant ad space
- Professional and novice publishers, bloggers, Redditors, what have you building websites and pushing out content that Google's web crawlers scan and classify in its index
- Data from other Google products, like Chrome and Analytics, that inform (if not directly influence) Google's understanding of content and search behavior
- Google employees using semantic analysis, pattern recognition, predictive analytics, user feedback and machine learning to understand what it all means and tweak the algorithm so searchers see the best results.
With these inputs, Google catalogs and categorizes related words and patterns, building entities, or a series of commonly used words or images related to a topic. Google's entities are extremely sophisticated, which is why searching "comic books" brings up not only the usual superhero suspects from Marvel and DC, but also independent comics like the Umbrella Academy... as well as legacy comics like Little Lulu.
Google's natural language processing capabilities identifies patterns not only in the word itself, but also in syntax and intent. When I search for "comic books" in the Keyword Planner, Google knows that I'm looking for drawn panels and weekly releases of sequential art books, not Tig Notaro and live events. A few years ago, the Keyword Planner and the Ads API wasn't quite as smart. But we all learn over time, and there's no shortage of comic book content online to help Google discern the nuances.*
The planner also understands my seed query's intent is to understand comic book series and not movies or TV based on superhero comics. Google's keyword database has memory, although it's never been clear to me how far back, which means that related keywords can appear next to a seed query for years after they've peaked.
*That said, I am surprised that there's not more on WebToons or manga in the keywords generated from the "comic books" query. It's another exploration for another time.
Search data as palimpsest
The concept of a palimpsest helps me comprehend how Google's database works: it's a document that rewrites itself and refreshes constantly, but traces of past iterations never quite disappear. This works fantastically for Little Lulu, a comic strip from the 1930s that still lingers in popular memory and search queries.

Keyword planner's memory not ideal for quickly evolving cultural norms, which you'll discover if you start researching topics related to race, gender, sexuality and religion.** Why does Google think that term is related to my seed query? is a rabbit hole of Wonderland scope where you're as likely to find singing flowers as that terrifying part where a baby turns into a pig.
Google's massive relational tables (smart spreadsheets), data storage, processing capabilities and advanced machine learning organize the keyword data. It's an astonishing act of computing so advertisers can find the right keywords for their entity, quickly and accurately. It exports this data for free via the Google Ads API because it wants to "freely encourage innovation," according to its documentation. Sure, but...
Giving away raw data and free training on its software has proved wildly profitable for Google. It's a juggernaut business strategy in the open source tradition. The more people who learn to use keyword data, the more people understand search engine marketing, the more ads Google can sell.
**Read Safiya Umoja Noble's Algorithms of Oppression for a detailed analysis of this problem.
How do non-Google keyword research tools work?
Keyword research tools are independently operated platforms that harness and organize keyword data from the Google Ads API, which mirrors but doesn't necessarily replicate the data in Google's Keyword Planner. The API is free, but for organic researchers who don't have regular access to a well-funded Google Ads account, accessing its wealth requires purchase of a subscription keyword research tool.
SEO tools often corroborate and merge Google's API data with other sources, including APIs based on publicly accessible Google Trends data, clickstream data (see below). With multiple data sources, keyword research software companies add an interface that operates similarly to Google's keyword planner: enter in a single query and you'll find dozens of semantically and topically related queries.
Most keyword research tools provide the following metrics:
- Average monthly search volume: the number of times a specific query is searched each month
- PPC/CPC: the average cost per click for a keyword, useful for paid media planners
- Trending search results: keyword research tools can identify whether the query is consistent month over month, a seasonal surprise, or a one-time viral hit in the past year
SEO tools often supply other proprietary metrics, like domain authority or a keyword difficulty score. Each tool's data is a little different, and each will argue it has the best or most accurate data. My experience is that the data variations are negligible for current entity-optimized SEO and that teams and keyword researchers should find the interface they're most comfortable with.
Deborah Carver
I use Mangools these days.
What is clickstream data and how does it factor into keyword research?
Clickstream data originates from free browser extensions that record keystrokes, clicks and searches in browser. Users install the browser extensions for free, and then which the browser extensions anonymize and export the data to third parties. The third parties organize and sell that data to software companies or agencies.
Does that sound shady to you? It should give you pause. Some anonymous company tracks all your clicks and keystrokes without your knowledge and then selling that data without your knowledge.
SEO tools that use clickstream data insist that it's opt-in, but I don't know anyone who can tell me the contents of their browser extensions' terms of service. It's anonymized data that's only useful in aggregate, but most users opt into surveillance of their keystrokes unknowingly. That said, clickstream is not much different than typing a search query into Google and using the search engine for free without thinking about where the search term data goes.
By the time it gets to any keyword research tool, all keyword data is anonymized and stripped of personally identifiable information, so unless you type "my name is Deborah Carver and I'm looking for information about comic books" into your search bar 1000 times in a single month, it's unlikely that your deepest, darkest search queries will be linked back to your name and IP.
Just make sure you trust your browser extensions.
Deborah Carver
If it's a little shady, why use keyword or clickstream data at all?
As Rand Fishkin and others have pointed out, clickstream and other supplemental data sources keep Google honest to some extent. Otherwise, we are at the mercy of the benevolent giant to tell us the truth.
But at least Google currently provides its data to researchers. Most other platforms are "walled gardens," meaning that they provide very little of their source data to outside sources. With keyword research data, I can go back to clients and make very specific recommendations on content areas and keywords we hadn't considered in our initial discussions.
Keyword research also helps stakeholders understand that people don't use marketing speak in their search terms. People also don't search with the same words they use to talk or chat or tweet. Imagine if, when suggesting dinner, your partner said, "pizza near me now." No one talks that way.
Many people search that way—17,800 times each month across the globe, on average. Search language is its own behavior, one that's ever-evolving.
Some parting advice to keep in mind with keyword data:
- Don't take absolute search monthly volume as a set-in-stone fact. The value of keyword data lies in trends over time or comparison to other keywords.
- Automated research tools may guess intent, but the best way to learn intent is to read and manually organize your research.
- A single keyword is never the ticket to optimization success. The key is to understand the entities: how different terms relate to each other in aggregate and why.
Next month: An overview of my keyword research techniques. In the meantime, here's more information on keywords from WTF is SEO:

Hand-picked related content
Deborah Carver Deborah Carver
Deborah Carver Deborah Carver
Deborah Carver