This essay originally was published on March 2, 2023, with the email subject line "CT No.157: Art in the style of SkyNet."
When SkyNet finally arrives, it will probably be because somebody ambitious thought they had invented a terrific new way to cut corners.
With workers reluctant to return to offices—and staff positions with perks like health insurance thin on the ground—more employees are striking out on their as freelancers in the gig economy. In the media industry, where I’ve spent my career, employers seeking to cut costs shift greater burdens of labor onto their remaining employees. The corresponding gaps in staffing and budgets can’t be filled by gig workers, many of whom use their contingent position to avoid scutwork. Tasks like writing press releases, generating boring news items, or making the hundredth photo illustration of Donald Trump with his pants on fire tend to get shunted over to shrinking numbers of hapless staffers.
Now, some businesses are trying to automate that scutwork using tools we’re calling “artificial intelligence” — a designation of which I'm nearly always skeptical.* Some tasks will always require a little creativity to complete, and now, we are told, computerized minds are capable of “learning” how to make honest-to-goodness art utilizing vast stores of digital and digitally duplicated art as its machine-learning MFA. (The FTC shares my cynicism, and urges companies to not to overpromise what an algorithm or AI-based tool can do or deliver.)
Typically the use of all that data is ethically justified by Whole Earth Catalog creator and hippie deity Stewart Brand’s deceptively simple axiom, often repurposed by tech execs, that “information wants to be free.” Creators of information, by contrast, want to be paid. Robots work free — it’s in the name.
And as we all know, giving robots unpleasant tasks leads to robot problems.
*Remember Elon Musk’s dancing robot?
Carefully curated metadata versus messy user-generated uploads
One of the big problems of the internet has always been information hygiene—that is, the way we organize and index our near-infinite supply of data so that we can actually use it. Digital versions of every film in existence or scans of every painting in your museum are no good if they’re not properly categorized.
We have different ways of structuring this data: There are recommender systems (search engines, like Google, that rely on machine learning); keyword matching systems (see Deborah’s piece here); metadata appended via digital asset management software; the hashtags enterprising social media users voluntarily add to their posts; and databases, like Netflix’s lists of TV shows and movies and their respective categories.
For tech platforms that allow vast, unregulatable numbers of people to submit information to their databases—think YouTube, Twitter, and Amazon, to name three—this problem has gotten much worse in the recent past. Both savvy and spammy publishers attempt to optimize (encouraged!) or elbow their way into (risky or illegal!) search results and algorithmic feeds.
Content optimization doesn’t translate in the real world. Nobody from the Picasso estate hangs around the Metropolitan Museum of Art trying to convince curators to categorize Pablo as an impressionist so they can move more branded umbrellas.
But online, we've made it easy to access a Picasso, and to download a nice-sized image of one (even though his work, which is not yet in the public domain, is available at lower resolutions than, say, Hieronymous Bosch).
And if an AI art-generator company creates a program that can download images at scale and then mash them all together at an end-user’s command, creating endless iterations of digital images "in the style of the Blue period," we'll soon have a much larger database with even more images tagged "Picasso."
Midjourney meets copyright law
Generative AI art startup Midjourney uses “a hundred million” images, according to founder David Holz, and to achieve that kind of scale, Midjourney doesn’t discriminate between images in the public domain and images under copyright, nor does it provide a way for artists to forbid Midjourney from “training” itself on their work.
If an image is on the internet, Holz considers it his to use irrespective of copyright status. “There isn’t really a way to get a hundred million images and know where they’re coming from,” Holz told Forbes last year. “It would be cool if images had metadata embedded in them about the copyright owner or something. But that's not a thing; there's not a registry. There’s no way to find a picture on the Internet, and then automatically trace it to an owner and then have any way of doing anything to authenticate it.”
This is, to put it mildly, an absurd thing to say. There are lots of ways to know whether work is protected with copyright. For example, if you would like to know whether a song is copyrighted, try posting it to YouTube. You will learn that there is a robust apparatus for removing copyrighted songs from that service and a corresponding legal apparatus for prosecuting people who repeatedly try to distribute them for free.
What may be true is that there are not enough fair-use images available for Midjourney to do what its users want to ask of it, and that metadata isn’t always available for useful images. Many sites, notably Twitter and Facebook, strip the metadata from any image uploaded by a user; cameras and cell phones can accidentally give away compromising information. But not all sites do this—Flickr, for example, definitely does not—and Midjourney doesn’t check.
Midjourney also has to have some sort of authorship data about the images it lifts—otherwise it can’t know how to draw Garfield in the style of Roz Chast. When a computer program crawls an artist’s website, lifts their work, correctly attributes it to the artist, and then reissues it in that artist’s recognizable style, that is a problem. Technically speaking, it’s not much different, as Sarah Andersen noted in the New York Times, from far-right trolls changing the text of her comics and distributing them to promote an ideology she finds abhorrent. (Andersen is suing Midjourney and Stable Diffusion.)
{kind=link}

Metadata, image collections, and consent of the artist
There are no universal standards for image metadata. But there are norms, and those norms are specifically designed to make copyright and usage conditions clear. The main innovation of Midjourney, Stable Diffusion, and other AI art startups is that they seem to be violating copyright at scale (hence the lawsuits, also at scale).
More to the point, there’s no standard for granting consent, which is Holz’s only real problem. If you want to license a cartoon from The New Yorker, where Chast publishes much of her work, you can do so easily—Condé Nast has a huge database of its licensable cartoons free for the browsing; it’s a great way to kill an hour or blow a deadline.
But if you want to reproduce the images, it’s not free. Condé will collect. Artists can charge you to use their work. Or they can say no.
Unless you don’t ask.
You don't have to ask to crawl and categorize images in a database. But if you don’t ask, rights-holders can sue.
Is AI-generated art a useful tool?
It’s worth noting that AI tools are terrible at rendering many things—fingers, for example. Midjourney can beautifully render a reflective surface, but so can painter Julie Bell. If I ask Midjourney to draw in the style of Julie Bell, it spits out images that look nothing like Bell’s paintings. ChatGPT can’t write a limerick to save its life—and a limerick is a poetic form with a very easy set of rules.
Proponents of AI art are quick to defend programs like Midjourney as mere tools, to be used by creative people who need shortcuts. And there is plenty of precedent for the use of good digital tools: Comics artists who work solely in ProCreate tend to work much faster than those who rely on pen-and-ink drawings.Unless you are working on the latest issue of Batman and can sell the individual pages to collectors, digital art is far more cost-effective, too.
Midjourney may present other, non-logistical problems to users trying to create new work with its help. For one thing, the U.S. copyright office won’t grant copyright to artists who use AI to create their images.
For another, AI doesn’t always alter the work it trains itself to copy as thoroughly as ethical standards require. Neither do people, but people can be fired.**
Recently, publications as large as Sports Illustrated and CNET have sought to harness AI to handle the composition of news stories, and have immediately run afoul of plagiarism checkers. At least one unscrupulous artist took sketches in process and used AI to beat the manual artist to the finish line, then accused the original artist of theft. One artist found that it wasn’t just her art that had been used as training material for AI art programs: photographs she had provided to her medical doctor had been used in violation of medical privacy and consent data laws.
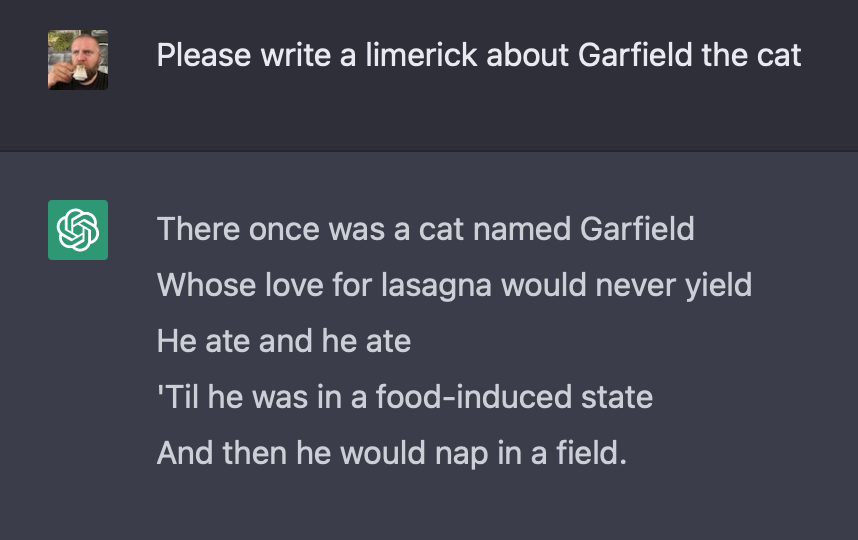
**To avoid being fired, fair use standards can be found here. [We maintain that both works above are considered "fair use" for the purpose of education. —Ed.]
Protecting your digitally published artwork from the machines
So what’s a content manager to do?
- Whether you’re a content creator or in charge of an institution with a large cache of material you’d like to keep available to the general public, but not to robo-thieves, the good news is that tools are already being built to keep your — and your company’s — work off Midjourney and similar services. But don’t count on the AI-makers to provide them: HaveIBeenTrained.com is a project of Spawning.ai, an artists’ group, that lets you search for your work in image databases frequently crawled by AI artists.
- If you’ve been ripped off — or if your carefully written Creative Commons license hasn’t been honored — there are legal recourses, including several class action suits currently in motion. You don’t need to do anything to join one of these suits, but if they’re decided in favor of the plaintiffs, any harm done to you may be covered by the decision, in which case you’ll want to know about the progress of the cases. (Class Action Tracker is good for this.)
- The HaveIBeenTrained folks also make Spawning, which includes AI art tools populated exclusively with images for which explicit permission has been given to the creators. You’ll probably have some trouble getting a good image of Garfield, but if you just want an orange cat, it seems like a good place to start.
There’s a tendency among forward-looking CEOs and marketers alike to allow AI to make big mistakes and write them off as embarrassing whoopsies in the service of a grand idea. And to be fair, tools like Midjourney, ChatGPT and Stable Diffusion are fun to play with, and their appropriation of hundreds of millions of images is breathtaking in both scope and audacity.
But those mistakes can be quite dangerous, both in terms of compliance and liability and, when we start talking about sectors like automotive automation, to life and limb. Teslas are perfectly fine electric cars; trying to make them into the self-driving car of the future has turned the company into a punchline.
The point, as always, is to be good at what you do, not to train a robot intelligence that will make you obsolete. That’s how you get Terminators.
Nobody wants Terminators.
Sam Thielman is a reporter and critic based in Brooklyn, New York. He has written widely on technology and business as a tech reporter at The Guardian’s business desk and as Tow Center editor at the Columbia Journalism Review. In 2017, he was a political consultant on Comedy Central’s sketch series The President Show. He currently edits Spencer Ackerman’s newsletter FOREVER WARS and writes about comics for The New Yorker.
Hand-picked related content