
First, a semi-important introduction:
When I studied abroad in Prague in 2003, the curriculum centered on how to avoid a police state. The Czechs, whose country was essentially a bargaining chip for two successive totalitarian regimes, understood the bellwethers of repression and political violence. My professors, at least one of whom had been an active dissident in the 70s and 80s, described the signs and signals of encroaching political violence and change. As a student, I admired their bravery but never once thought I'd be recalling their words while watching everything they warned against happen again, this time in my country.
We are not at totalitarianism yet, technically, but with this week's baseless military takeover of Washington, D.C., looking away hasn't been an option. How am I supposed to get anything done when everything I've been taught to recognize as signifiers of authoritarianism keep happening? When it seems downplayed significantly by major news sources and ignored by internet pundits and their ever-increasing share of influence?
It's not healthy to panic. It's not healthy to doomscroll. It's not healthy to focus on the negative. It's not healthy to think about how, with all the education and tools in the world at my fingertips, all the warning signs I know, I can't stop or affect any of it. I have never felt so powerless.
When the National Guard was deployed to my neighborhood in Minneapolis in 2020, the stated purpose was to keep peace between the protestors and the Minneapolis Police Department. But it certainly didn't help that the guard deployment was coupled with, "When the looting starts, the shooting starts." In the days following the deployment, my liberal sanctuary city erected barbed wire on large portions of my street. Even though the only human casualties during the protests were courtesy of MPD, whose less-lethal weapons were aimed directly at protestors and journalists.
Helicopters circled low around my neighborhood for months. The barbed wire didn't come down for years. I find that most people outside Minneapolis don't know how bad it was, and they have no idea how long it lasted because "the barbed wire is still here" is not news. Most people experienced the protests after George Floyd's murder as a blip on their feeds, not an environmental and social transformation.
I was raised to trust the police and the military. Close friends and family are veterans. I respect them for their service. My current fear is a learned behavior based on personal experience.
Experiencing a police state, even temporarily, is different than watching films or reading books about police states. It's different than watching a police state on the news, which creates a level of familiarity with the image but abstraction from the actual violence. The size of a tank on a tv appears equivalent to the size of the news anchor's head, but when that tank is in front of your house, it's a very different story. You can't look at your phone and swipe to the next piece of content when your city is occupied by the military.
Don't let anyone tell you "most people don't care that much." If the kicker of this Sicha/Scocca CNN story reads literally, there is adequate reason to care. Whether you call them the Gestapo, the Stasi, the NKVD, or ICE, it's impossible to look away when the enforcers are in town.
D.C., I see you.
(And I'm remembering the stories my dissident professor shared about how absurdism distracted and confused the authorities. How comedy was effective in relieving the tension. So, Subway Hero, thanks for taking one for the team. I'm sorry you got charged with a felony because a group of goons strapped with assault rifles feel threatened by a airborne Italian BMT. I only wish you had gone down the street and chosen Ben's Chili Bowl as your drunk meal.)
Ok. It's time for tokens and vectors. I very much believe that understanding the AI systems that are poised to control information will help us fight the power one day.
–DC
Tokens and vector embeddings: The first steps in calculating semantics
This is the second post in an ongoing series about the mechanisms behind how natural language understanding (NLU) reads content online.
Read the first essay in this series.
For the first time, I used Claude extensively to help me define, rewrite, and fact check the concepts in this week's newsletter. Nearly every explanation of tokens and vector embeddings I've ever read is highly technical, and I have never taken a comp-sci class. Even after years of "understanding" the concepts in the back of my head, I realized my short-hand technical knowledge of "tokens=words; vector embeddings= word-shapes" was off-base. Here's hoping Claude didn't hallucinate and misinform me, and I'm not, in turn, misinforming you. I'll include some more technical links at the end of this essay, if you want to fact check me or look into the particulars.
Tokens: Giving every word part its own special numeral
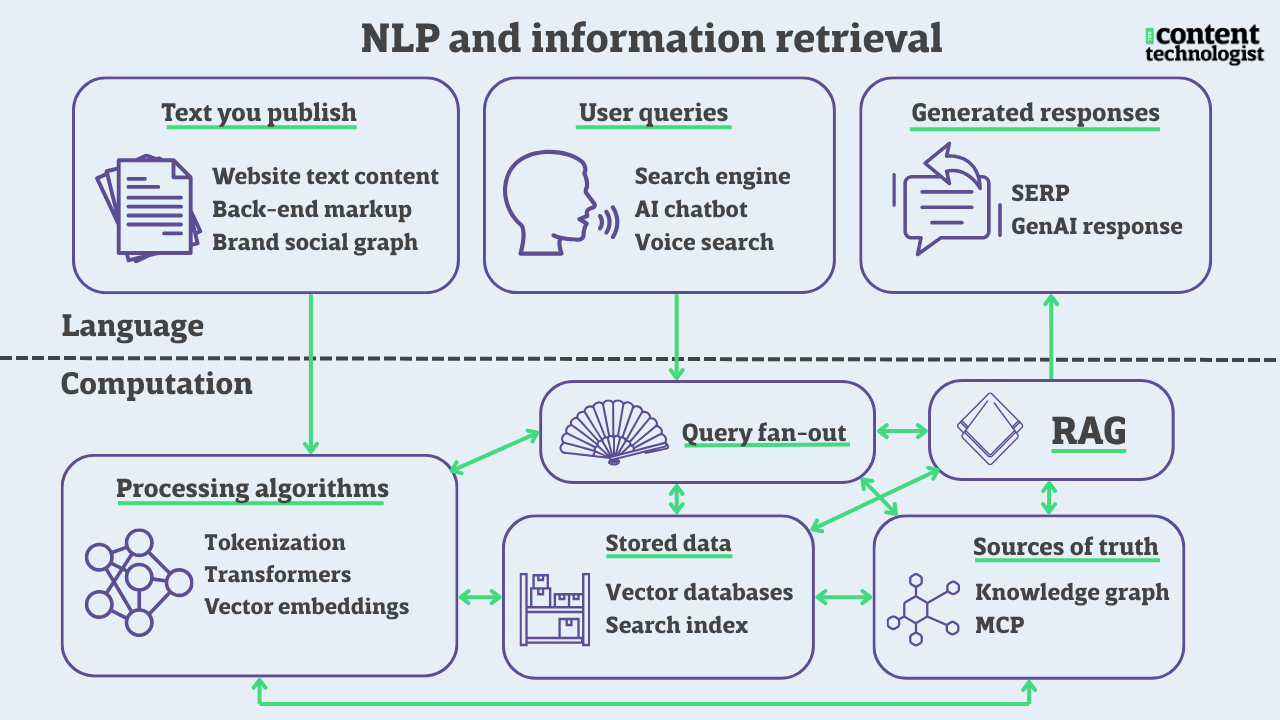
The first thing to know about "tokenization" in natural language processing is that it is quite the opposite of the "tokenism" you learned about during undergrad/ in grad school/ on South Park.* When we talk about "tokens" in cultural studies and sociology, we're talking about a situation of performative exceptionalism: the few students of color at an otherwise white college who appear in all the promotional brochures or the lone woman on a corporate executive board. When we talk about "tokens" in natural language processing, we're discussing stripping language down to its lowest common denominator and converting it to numbers, making the word anything but exceptional.
Tokenization in natural language understanding (NLU) is also different from tokenization in blockchain/web3, which describe the encryption of sensitive data. NLU tokenization is not sensitive or encrypted in any way; in LLMs, tokenization simply represents a word, a part of a word, or a character as a numeral.
But let's consider "tokenism," "tokenization (NLU)," and "tokenization (Web3)" as, well, tokens.
*I apologize, but because South Park's first season coincided with my freshman year of high school, it *was* how I was initially introduced to the term.
What is a token in natural language processing?
Tokenization (NLU) breaks down words into their most useful parts, so that the relationships between words can be mathematically calculated. We can tokenize whole words or individual characters, but neither of those methods is particularly efficient. What's more effective is somewhere between etymology and phonics: natural language understanding systems break down words into parts, effectively "sounding out" the word like a young reader. So:
- "tokenization" > "token-" and "-ization"
- "tokenism" > "token-" and "-ism"
This example breaks nicely into morphemes, or the root word and suffix. But not all tokenization is morpheme-perfect because languages are full of exceptions. From what I gather, most of the tokens used in contemporary natural language understanding are actually subword tokens, often the lowest common denominator string of letters. So:
- "strategic" > "strate-" and "-gic"
- "strategy" > "strate-" and "-gy"
"Strate" is not a word, nor is it a proper morpheme. It's just the common root string, or list of text characters, in a root word.
- "efficient" > "efficien-" and "-t"
- "efficiency" > "efficien-" and "-cy"
"Efficien-" doesn't mean anything to English-speaking humans, but to a computer trying to understand English-speaking humans, the string "efficien-" is enough to understand that the string represents a number that can be substituted for the meaning "quickly, cheaply, and with purpose."
Every string of characters is then converted into a numeral. For example:
- "strate-" = 15847
- "-gic" = 29384
- "-gy"=18294
Thus, "strategic" tokenizes as [15847, 29384], and "strategy" tokenizes as [15847, 18294].
Tokenization is part of data pre-processing before training LLMs and essentially define an LLM's vocabulary. Models are trained on billions or trillions of tokens, and those are reduced (like a balsamic glaze) to a much smaller and more workable vocabulary. Depending on the language and the model capabilities, tokens are further compressed with technologies like Byte Pair Encoding (BPE), WordPiece, and SentencePiece.
You're likely most familiar with tokens as the input-output limits of each model. When the LLM cuts you off or tells you to wait a few hours, it's because too many tokens have been consumed.
From tokens to vectors: Making sense of words through their relationships to other words
Tokens are relatively easy to understand, but vector embeddings make the concept more complex. If you remember geometry class... well, I don't remember the role of vectors in geometry, but I remember that the entire field of geometry describes mathematical relationships represented in space. I also remember that "vectors" were part of physics, so I know vectors have something to do with how words, or tokens, relate to each other in some kind of multidimensional space.
Changing words into multidimensional representations enables computers to represent and calculate semantics. Essentially, vector embedding turns words into points in mathematical space.
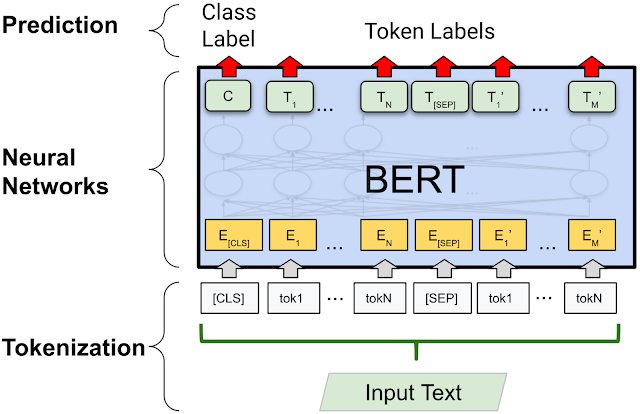
In natural language understanding, vector embeddings describe relationships between multiple tokens that are semantically or contextually related. Models like Word2Vec and neural networks analyze how tokens co-occur and interact throughout a training dataset, learning common patterns and relationships among tokens. Vector embeddings are stored in a large language model's parameters, memory, and supplementary databases, enabling LLMs to encode and process semantic similarity among tokens.
If that's not crystal clear—no shame, and I'm a bit in the weeds articulating it—here's an example:
- We are strategically optimizing our business for efficiency.
- Efficiency powers our strategic business optimization.
Each token receives its own vector embedding——a list of numbers that represents its meaning as coordinates in multidimensional space, where semantically similar tokens are positioned closer together.
Both sentences share similar tokens, and the vector embedding describes how each tokenized word relates in space to every other token. Tokens with similar semantic relationships have vectors in close proximity to each other. In language terms, vector embeddings are great at identifying synonyms and often-paired subject-verb-object relationships.
A natural language model can understand similarity among vectors in the sentences above and understand that both sentences are about business strategy, efficiency, and optimization. They share more or less the same meaning, expressed in a slightly different form, because the vector embeddings are similar.
Context is here vector embeddings alone fall flat
But let's look at a different example:
- I felt tokenized when I was the only woman speaker at the conference.
- We tokenized words into subwords to process the corpus accurately.
While both sentences share one of the same words (or tokens), they mean wildly different things. In the first sentence, "tokenized" refers to "tokenism," or the feeling of being an object of performative inclusivity. In the second, "tokenized" refers to the linguistic and computational process of breaking down words, as described above.
Vector embeddings struggle with polysemy, or when the same word carries multiple meanings. The word "tokenized" would be represented with exactly the same vector embedding, even though the meaning of the word is extremely different depending on the context of the sentence.
Vector embeddings alone aren't enough to understand the complex relationships between words, sentences, and paragraphs that create meaning in language. Word2Vec was a big step toward today's LLMs, but it only tracks shallow relationships among words.
Since nearly every common term in natural language understanding has another meaning outside the field of computer science—"tokenized" being the first of many examples—NLU researchers created a mechanism to differentiate contexts. That invention, also from the researchers at Google, was the transformer, which we'll discuss next week.
Some technical explainers on tokens and vector embeddings that helped me understand what I didn't know:

Content tech links of the week
- Although I initially dismissed the first few paragraphs as "some fantasy nerd hallucination bullshit," in the context of tokens, vectors, and the shared AI corpus, Max Read's Who is Elara Voss? is fascinating and weird.
- The primaries at Trust Insights, Christopher Penn and Katie Robbert, noticed differences in how transcription tools treated their individual contributions to a podcast. They uncovered a fascinating case about how authority and bias is replicated by AI that I'd never even considered. (I generally don't listen to work podcasts, but this is worth it.)
- Matt Klein and Brooks Miller nail all the failures of the creator economy and why it's a horrific model for making a living from creativity.
- Dan Hon offers a novel solution for how, with the right governance structure, national copyright libraries could have (and could still, although it's unlikely) created a more ethical and legal machine learning foundation for generative AI.
- On the content engineering side, Marc Salvatierra proposes a standardized system of content modeling.
The Content Technologist is a newsletter and consultancy based in Minneapolis, working with clients and collaborators around the world. The entire newsletter is written and edited by Deborah Carver, an independent content strategy consultant.
Affiliate referrals: Ghost publishing system | Bonsai contract/invoicing | The Sample newsletter exchange referral | Writer AI Writing Assistant
Cultural recommendations / personal social: Spotify | Instagram | Letterboxd | PI.FYI
Did you read? is the assorted content at the very bottom of the email. Cultural recommendations, off-kilter thoughts, and quotes from foundational works of media theory we first read in college—all fair game for this section.
If the subject line of this newsletter is familiar to you, or if you need goofy jokes to keep authoritarianism off your mind, I recommend the reboot of The Naked Gun.
