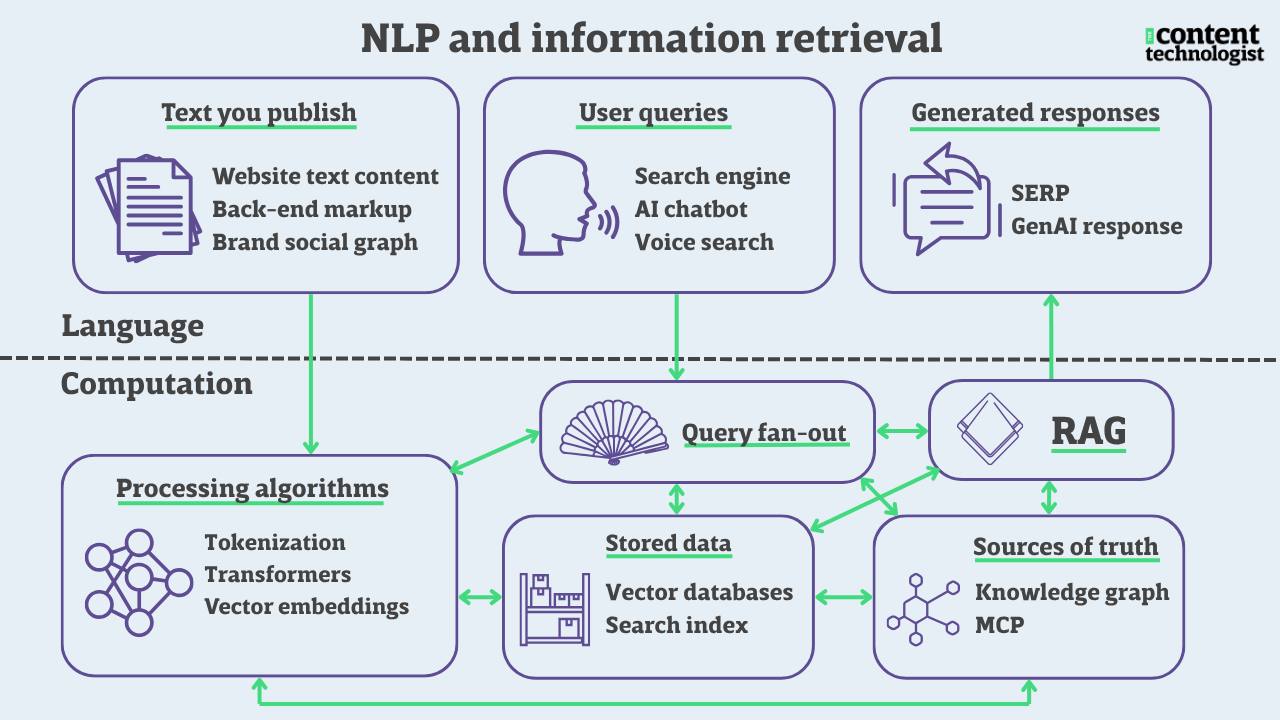
This is the fifth essay in an ongoing series about the technologies that underpin natural language understanding (NLU). This week's essay expands on the concepts of vector embeddings and transformers.
"Listen to this song and write down all the nouns you hear," Mrs. Rich instructed our class of 30 fourth graders. It was 1992 or '93, at a small parochial school, and all media was on some tape or other. She pressed Play on the boombox, and the cassette rolled into an opening tickle of the ivories, followed by a harmonica: the song we were to noun-out was "Piano Man."
Most of us knew the song from our parents' radios, and at least in the greater Philadelphia area, "Piano Man" was considered family-friendly fare. The song was 20 years old, and from a more innocent time, especially when compared with one of the most popular songs in America, "Baby Got Back." As a junior pop fan and piano player, I excitedly started cataloging all the nouns I heard: "Saturday," "crowd"... but what am I supposed to do about "tonic" and "gin"?
We listened to "Piano Man" about four times, with Mrs. Rich rewinding and re-queuing the tape each time. And then the class discussed the different types of nouns we'd heard. Proper nouns like "Davy" and "Bill"; things like "memory" and "microphone"; people such as the "waitress" and "businessmen"; and places like "bar" and... well, "bar" is the only place-specific noun in "Piano Man."
The class stumbled around some of the more challenging concepts: What are we supposed to do about "nine o'clock"? How about "a drink they call loneliness"? "Making love"? "The businessmen slowly get stoned"? Ten-year-olds don't miss much when it comes to naughty adult words.
Listing all the nouns in "Piano Man" is a challenge, even for the most grammatically and culturally savvy adults. Classify the nouns in "Paul is a real-estate novelist" in a couple of seconds without double-checking your answers or pausing on what it means. Does he write fiction about real-estate (yikes) or is it more like "real estate / novelist"? Frankly, both careers would leave plenty of time for a wife.
Regardless... I think about this single remaining memory of my fourth grade teacher—and how I'm glad I am to have been raised in the decade before Kidz Bop—whenever I encounter the phrase "query fan-out."
How Google fans out search queries
Query fan-out is how Google describes its process of evaluating the complex queries that generate AI Overviews. Introduced in Google's official blog announcement of AI mode, the term explains how what we type into the search bar is modified and personalized to produce an appropriate result. For example, if you were to type, "I want to create a playlist of well-known pop songs about dive bars," the fan-out begins with the relevant nouns:
- playlist
- songs
- bars
The search engine uses these nouns to identify the core entities and the intent of the searcher. "Playlist" is the subject entity, with "pop songs" as the specified genre. "Dive bars" is the object of the query. The transformer architecture behind AI mode then evaluates these entities based on their modifiers: "Well-known pop" when paired with "songs" indicates that the search engine might to scour Billboard Hot 100 Wikipedia lists. "Dive bars" means we're staying away from the club, ducking out of scenes from an Italian restaurant, and bellying up to beers.
Regardless of the modifiers around the query, the ten blue links on the resulting SERP are others' playlists on Spotify and Apple Music, a Reddit entry, and a couple of indie music blogs. The links themselves don't change much whether the query is "dive bar playlist" or "a playlist of songs about dive bars" or "I want to create a playlist of well-known pop songs about dive bars."
But the AI Overview above the SERP modifies its response depending on the structure of the original query.
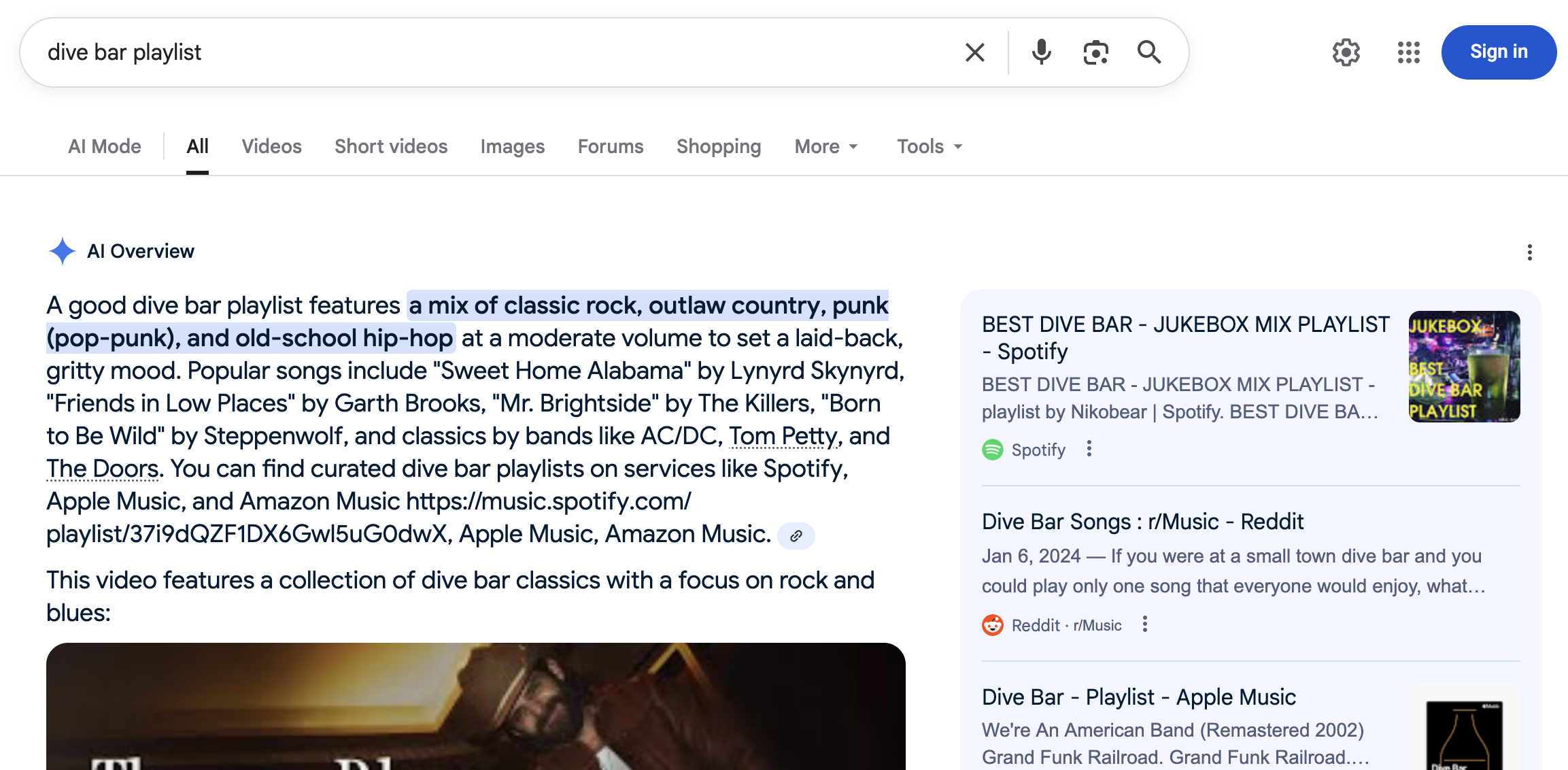
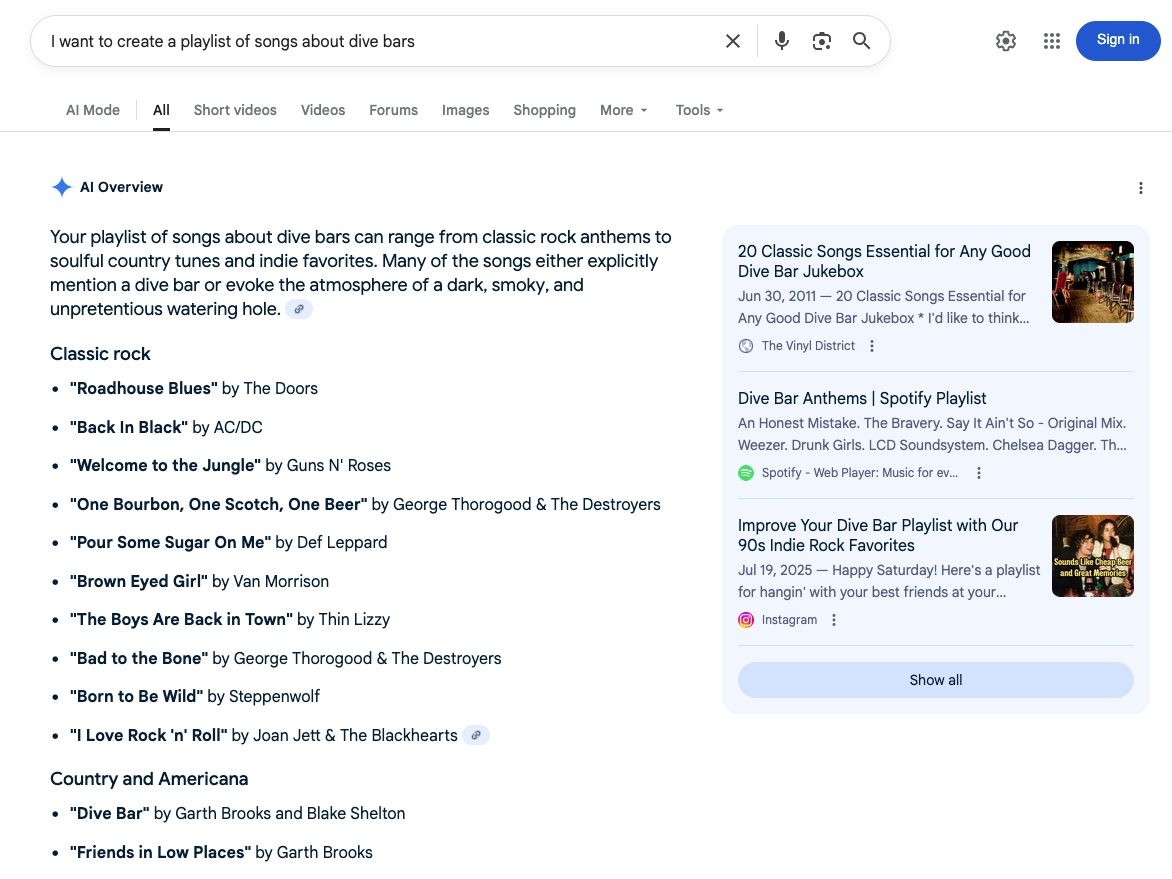
All examples begin with some introduction of what a good dive bar playlist entails, but adding "I want to create" elicited a more on-the-mark response and specific list of songs.
The fan-out of nouns and verbs in keyword-based natural language processing
Query fan-out is a new term for what's long been a bedrock of keyword-based language processing: the nouns are central to understanding the user's intent. Whether we type "brown shoes" or "birthday cake recipes," the system understands that we want to shop for shoes and not pants. We want to see recipes to bake a cake at home, rather than order a full birthday cake from a bakery.
Advanced keyword-based systems also understand the difference between the core query and its modifiers. The shoes can't be white or black or blue. The recipe desired is one for a specific type of celebration that, in American culture, is typically a vanilla-flavored confection, frosted and topped with sprinkles.
Keyword-based systems are built around nouns and their modifiers because the noun is the thing that the user seeks. But natural language processing (NLP) systems take the query further. The target noun in "first dance songs for a wedding" lies in the middle of the phrase, with the sandwich of "first dance" and "for a wedding" indicating an extremely specific subset of popular love songs. Google's Hummingbird update, all the way back in 2013*, introduced NLP to both query processing (user side) and content processing (publisher side).
Subject - verb - object, aka "semantic triples"
Natural language processing of the last decade also encoded the relationships between subjects, verbs, and objects. Those vector embeddings from a few issues ago? Google's been using them to understand frequent subject-verb-object combinations among navigation, headings, and body copy for years. Ideally, in text that hasn't been over-optimized, vector embeddings represent the most common nouns and verbs as they correlate with particular themes, topics, and user intent. For example:
- Spaceship > orbit > earth
- Couple > dance > wedding
- Bar > serve > drinks
In computer science, the subject-verb-object relationships are called "semantic triples," calculated as the core relationships among common phrases in a specific domain of knowledge. In ontology and knowledge management, semantic triples represent language and concepts in a database, like an object-oriented relational table. Since the 1980s, semantic triples have been used in knowledge management systems (i.e., corporate research libraries, site-specific search engines) to map relationships in domain-specific language.
In SEO spaces since Google defined "query fan-out" earlier this year, I've seen quite a few prominent thought leaders suggest optimizing for "semantic triples" to be cited in AI Overviews and LLM-based search. Yes, search engines and chatbots access stored embeddings of semantic relationships to quickly understand common subject-verb-object relationships.
But optimizing web content for "semantic triples" or intentionally placing subject-verb-object relationships within a text, is only a slightly more complex version of keyword stuffing and keyword density. Artificially overemphasizing certain phrases repeatedly throughout a text—what often occurs in the final "SEO edit" in publishing workflows—is a good way to over-optimize (or enshittify) what would otherwise be well-written content. And keyword stuffing hasn't been a reliable strategy for website optimization in at least a decade.**
**Most recently, I suspect keyword stuffing over-optimization strategies were targeted in Google's Helpful Content Updates, which led to a slew of complaints from prominent SEOs and independent publishers in 2024.
Don't overwork semantic optimization
Experienced writers and editors don't need to think too deeply about "semantic triples" because we already use specific nouns and verbs in our writing. "Semantic triples" are directly analogous to the building blocks of sentences (in English, anyway): subject > verb > predicate. Incorporating topic-specific nouns and verbs, along with defining focused brand messaging architectures, brings out natural connections among words without overworking syntax.
My understanding of how natural language processing works has been similar to "query fan out" for a long time. When conducting keyword research for search and discovery, I've long quantified and expanded upon particular relationships between the nouns and modifiers in search queries. I use those relationships to inform a brand's content strategy and information architecture, knowing that different combinations of modifiers, nouns, and verbs speak to different types of search intent and different audiences.
Quantifying combinations remains a highly manual process—aided by old-school language processing algorithms—but it provides a research-informed approach to developing content for search that is semantically evaluated, rather than scored by algorithms that do not comprehend context.
Transformer architectures have made it possible for natural language understanding to evaluate far more than nouns and modifiers. The patterns and semantics in the "large language" store of training data match similar patterns and combinations in the user's request. Using elite mathletics, LLMs and search engines convert words into math and back again, producing a response that feels human while addressing to all the fanned-out semantic specifics of a complex query.
But the meaning and function of the words aren't part of the calculation. And were it not for many close-readings of the lyrics of "Piano Man" available in the LLM's training data, chatbots wouldn't be able to decipher idiomatic phrases like
- "Son, can you play me a memory"
- "The waitress is practicing politics"
- "Put bread in my jar"
Those aren't common "semantic triples" outside of the song. In my fourth grade teacher's estimation, the relatively uncommon language in "Piano Man" made for a good exercise to see whether our class understood how nouns worked in colloquial context, rather than in written sentences.
How would chatbots perform in Mrs. Rich's fourth grade class?
None of the three chatbots I tested could perfectly identify the nouns in "Piano Man" because large language models do not know what "nouns" are. They understand how tokens and vectors match, not how parts of speech work. The LLMS likely contain structures created during pre-training and reinforcement learning that help the system understand English grammar, rather than the understanding of nouns I learned in Mrs. Rich's fourth grade class.
Claude performed the task much better than ChatGPT. It prompted me to enter the lyrics directly, citing copyright concerns. It misidentified "o'clock" and "tonight" as nouns on one try and hallucinated in "manager" during another. But otherwise, it would have done well in Mrs. Rich's fourth grade assignment.
ChatGPT repeatedly hallucinated the words "bartender," "friends," "light," "Sunday," "dream," "and "audience" into a list of the song's nouns. It's a typical hallucination, likely drawn from texts interpreting "Piano Man," like the annotations on Genius.com. While these are appropriate nouns from the semantic entity "Piano Man" inhabits, and present in the vector embeddings related to how the query "fans out," they don't appear in the text of the song itself.
Gemini performed the worst, inserting the words "bum," "cigarette," "mic," and "patron." It also amusingly drew from another part of the greater Billy Joel lyrical entity, throwing in "bottle" and "stranger."
The concepts behind "query fan-out" are not new to natural language processing, but with the new terminology, it's much easier for analysts to understand how simple tweaks in query and search history can change an AI prompt's result. But the connective tissue in NLU still needs some work. Google doesn't know the difference between intent for "songs about dive bars" and "songs for dive bars," no matter how I tweak the surrounding language. Perhaps it needs to be trained on "Busy Prepositions" from Schoolhouse Rock.
Bonus link
Michael Ian Black's McSweeney's classic: "What I Would Be Thinking About If I Were Billy Joel Driving Toward a Holiday Party Where I Knew There Was Going to Be a Piano"

Hand-picked related content