

From the earliest days of school, we're trained to think about math and language very differently. We learn to read and write in one class and arithmetic and algebra in another. Our math and verbal acumen are evaluated by completely different tests. And unless we take university-level computational linguistics and logic classes, most of us consider math and language to be different strengths and different subjects.
A major assumption: If you're here and you've previously read any of these 1,500-3,000 word newsletters, I assume you're a words person. Even if you were technically capable at math, you preferred reading and writing. When you craft content, you think about "hooks" and "narrative" and "syntax" and "flow" and "delight." You definitely don't think about the average number of syllables in each word compared with the number of words in the sentence. You think about what the words in the sentence mean and how, if you replaced them with other words or rearranged the order, how the meaning and interpretation of those words would change.
While you may be stellar at math-adjacent textual analysis skills like diagramming sentences or scanning poetry, it's unlikely you spend time considering how words are transformed into equations.
Language into math, math into language
Every time we type words into a search engine, an LLM, or any AI-powered text field, our words are transformed into numbers, a response is computed, and the response is then re-transformed into words. It happens so fast and with such complexity that even the most seasoned machine learning researchers don't know exactly what's going on.
That's why AI text generators are often considered to be "black boxes." The computations are so complex, rapid, and deep that we don't know how the generated text was calculated.
Even in the face of "black box" algorithms, the history of artificial intelligence—natural language processing, more specifically—has left plenty of clues. While we can't understand the full equation, and it's too complex to reverse-engineer it to meaningful outcomes, we can start seeing how the building blocks create common patterns in how current algorithms process language.
How language is processed for information retrieval
Everything we publish on our websites and social channels, every query we type into a blank field, and every computer-generated response is processed, multiple times, by algorithms we cannot see. A typical iceberg metaphor works here: the language layer is what we create and read with our human brains, while the computational layer is the mass beneath.
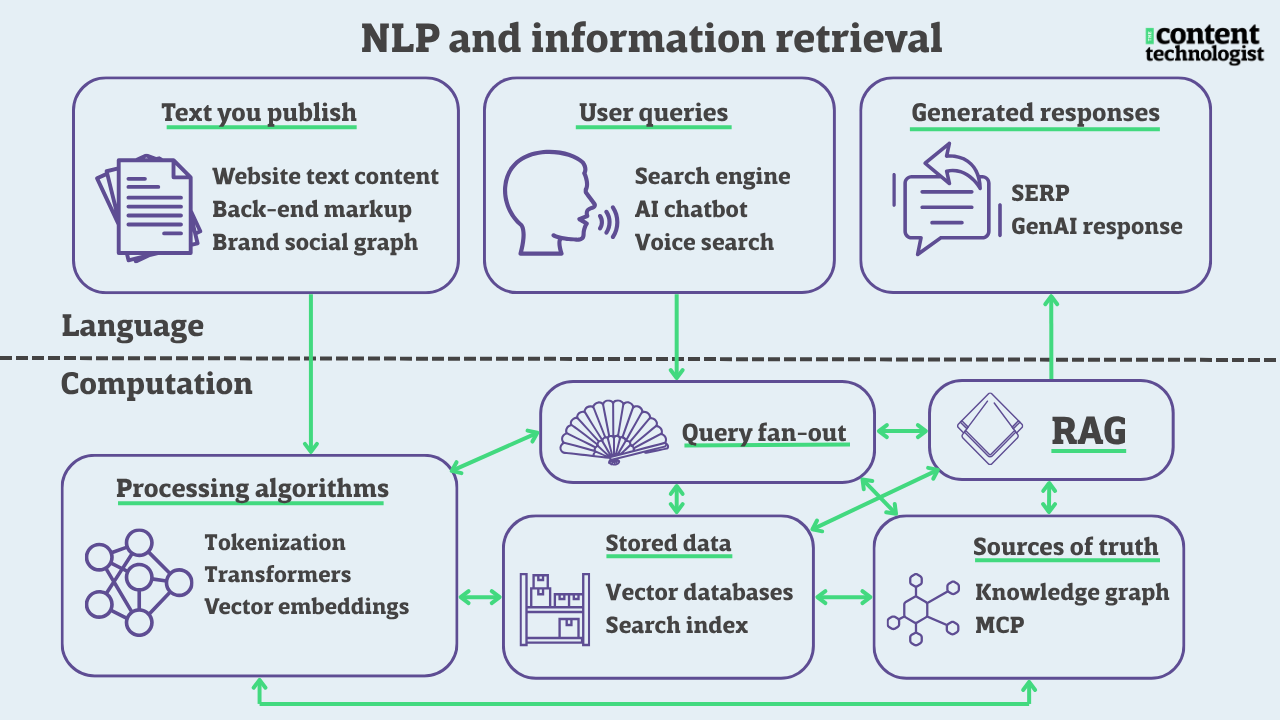
Please note: this diagram is an oversimplification intended for illustrative purposes only. Many folks smarter and more technical than I have created precise and complex technical diagrams of natural language processing systems. The above is intended to create a shared understanding of the amount and complexity of processing that we can't see.
As marketers and publishers, most of our online presence and reputation is shaped by the crawlable text that we publish. While external signals like reviews, social chatter, and press certainly impact performance, the text on our websites is still the source of truth about our brands for robots and humans alike. If we want to shape the end results to reflect our content and ideas accurately, we have to pay special attention to the text and structure of our website.
And as users, we have to understand that natural language understanding (NLU) algorithms transform our words into math the second we hit enter. The results we receive depend on the specific words we've used to structure our search term or prompt. When we choose one word over another—"boots" over "shoes" or "cake" over "dessert"—the response we receive reflects the language we've used, even when it doesn't come back in a pure echo response.
Over the next few issues, I'll explore the various technologies and algorithms in the computational layer. Because when you know how language models and search engines work together, the importance of researching, designing, and structuring content to for reading and interpretation becomes clearer.
The anxiety of influence: Early statistical language processing and understanding
The concepts behind natural language processing originated in a milieu of early twentieth century linguistics—this history traces NLP's origins back to Swiss theorist Ferdinand de Sasseur—but the conceptual groundwork for 2020s algorithms traces back to advances in applied statistics and computer science in the 1950s. Advanced statistics means sorting and cleaning large datasets, so algorithms were created to sort and identify common words in documents, apart from meaning.
The below formulas are not necessarily embedded into 2020s natural language processing algorithms, but the underlying concepts have a strong influence on statistical NLP, which powers large language models and search engine information retrieval. Understanding their functions makes it easier, for me anyway, to approach the far more complex algorithms we use today.
Regular expressions, or RegEx
Originally conceived in 1951 by mathematician Steven Cole Kleene, regular expressions represent typed character sequences as math equations. RegEx uses text characters (words) and common typographic symbols as metacharacters—or punctuation marks that represent symbolic functions.
In analysis, RegEx highlights or filters for certain characters and words in text while controlling for pesky punctuation marks, case sensitivity, plurals, inconsistent formatting, and surrounding language. RegEx identifies words and expressions in large, dense datasets, which makes them invaluable in content analytics.
Regular expressions treat words purely as symbols and do not process meaning in any way. But they find what you want, and they can count and analyze far more accurately than a genpop LLM.
RegEx is extremely common in Javascript, Python, and other programming languages. For us non-coding content strategists, RegEx is a thorn in our side, a necessary layer of word-math to help us understand which content on the website meets our needs. Google incorporates RegEx filtering into both GA4 and Search Console. For example, I can find all of the posts on my website with the word "analytics" or "data" in the URL, regardless of case, with the RegEx:
.*(?i)(?:analytics|data).*
When deployed as a regular expression, each symbol above represents an action. The period means "match any character"; the asterisk means "anywhere"; and the (?i) means "case-insensitive." Literally, the expression means "Match any character, anywhere, no matter what the case, with the words 'data' or 'analytics.' Doesn't matter what comes before or after those characters, any usage is fine."
Advantages: Amazingly necessary. Regular expressions are wonderful at filtering language and rigorously sorting data, if you already know which words and expressions you want to highlight. RegEx is a hard filter, compared with AI-powered sorting mechanisms that miss things. If you ask an LLM to help you sort and classify text, it's likely going to direct you to install Python and use RegEx
I have been familiar with RegEx since it was required for the Google Analytics certification exam in 2013 (the last math test I will ever study for), but mostly I only used ".*" because constructing RegEx is a challenge. But LLM chatbots excel at creating RegEx strings—one of the only areas where AI reduces my work—so I've been using them far more often in the past couple of years.
Disadvantages: Old and rigid. Truly, it feels like we should be beyond RegEx by now, but it's still the best go-to for cleaning and understanding messy text data. Best for language filtering or identification and not language understanding.
Flesch-Kincaid scores
You’re most likely familiar with these old friends of language formulas, which have been included in Microsoft Word since the beginning of time.
Flesch–Kincaid scores were developed in the 70s in the U.S. military. They remain widely used throughout software and incorporated into public policy as a measure of “readability,” for better or worse. The formula assigns lower grade levels to text with words that have fewer syllables and sentences that have fewer words. It's very easy to manipulate—replace a shorter word for a longer one, or vice-versaFor better or worse, Flesch-Kincaid targets are used in corporate communications
Advantages: Super common! Intro-level language algorithms! Helps steer teams toward plain language and away from jargon.
Disadvantages: Does a word’s syllabic content actually reflect its complexity? What happens when there are multiple meanings squirreled away in one-syllable words? How much has written language changed in 50 years? Should we update this formula?*
*Many thanks to a former client of mine who created an entire deck explaining why Flesch–Kincaid scores were detrimental to that company’s content strategy.
tf-idf
Also originating in the 1970s, tf-idf is a common statistical formula used in search engine ranking and document search. It identifies the number of time a word is used in a document or webpage (term frequency, or TF), compared to other documents in the same dataset/search query (inverse document frequency, or IDF).
For example, the term “icing” would often be in close proximity to “cake” in content about cooking or cake decorating. However, “The” is a common word everywhere, so even though “the” might be in an article about cake decorating, it’s not considered unique to the topic.
Implemented correctly, TF-IDF identifies and weights which words are unique to a topic or entity as compared to other topics. Like RegEx, it's an old but invaluable formula for content strategists seeking to understand large sets of text like customer interviews, user research, or large websites. I'd argue that tf-idf-informed analysis leads to more accurate summaries of large content sets than a genAI tool alone (which tend to focus on what's first in the corpus rather than common occurrence).
Advantages: Remains a fantastic way to prioritize which words are meaningful in a group of documents among the garbage words. Highlights words that are unique or common to a particular topics in very large websites or across competitive content sets.
Disadvantages: If over-relied on for sorting and ranking, tf-idf alone can discourage new perspectives or unique ways of writing about a specific topic. Over-relied upon by folks who believe in "consensus content" (often called "SEO content") versus unique brand positioning and voice.
All three above are old formulas, but commonly used and readable in LLM and search engine outputs. Why does ChatGPT default to overlong sentences with multisyllabic words? Blame the prominence of Flesch-Kincaid. Are you curious why all the links on the SERP have eerily similar content? You've identified an over-reliance on tf-idf. Why does Claude always recommend using RegEx in Python to sort and categorize text? Because it's the oldest, most reliable one of the bunch.
None of the above is a black box, but they may be components in complex black box computations. Because they've stood the test of time, they're highly represented in training data, both implicitly and explicitly.
Hand-picked related content



