

How does AI work? When academic machine learning "we don't know" how generative AI works, they're referring to how different innovations work together to produce credible language. We don't know how the compute layer works, mathematically, and at scale.
But as practical users of the inputs and outputs of generative AI, we can understand the piece-by-piece process of how machines process and value language. We can wrap our heads around how to create content to be read and understood by machines, so that it can be retrieved via search engines and chatbots. We don't need to know the exact calculations to understand the inputs, outputs, and outcomes of generative AI.
This series aims to explain the practical technology behind how computers process language. We're going through all the concepts in the below diagram, outlining how they interact, understand, and amplify content.
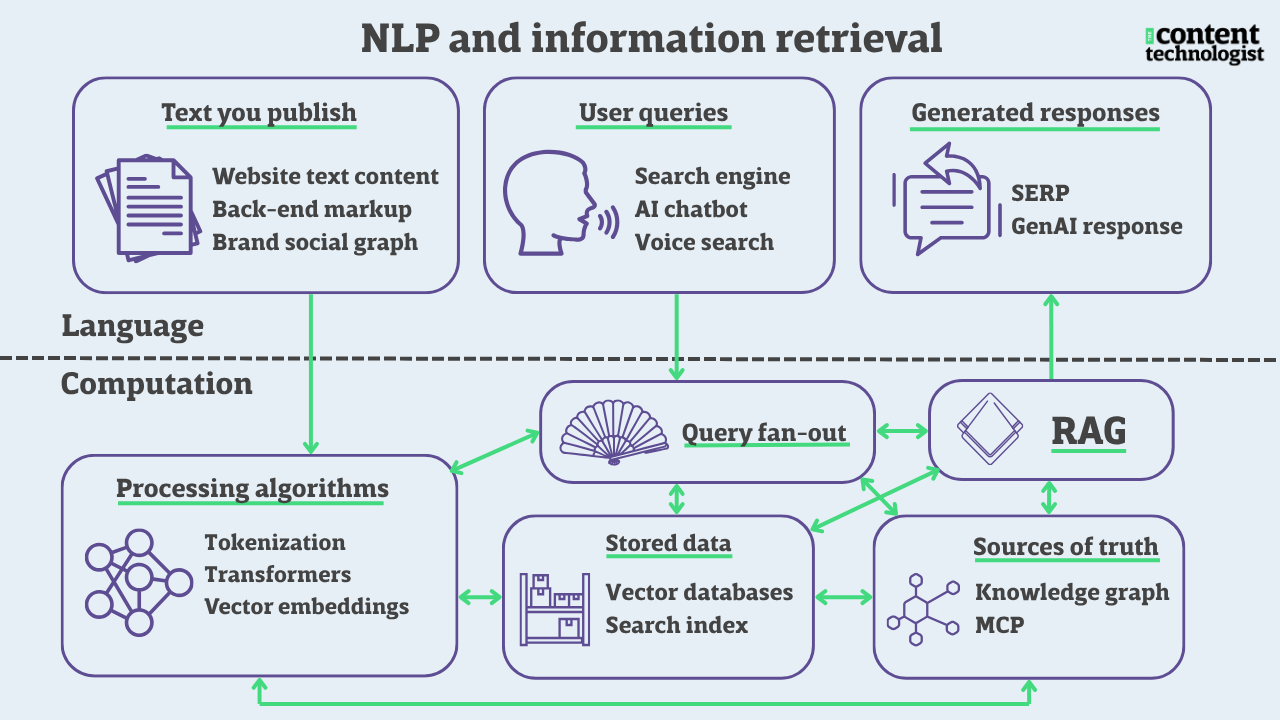
Terms and tools to master semantic optimization and contextual discovery
If you're reading this website and newsletter, it's likely you value structure in some form. Your title or vocation probably involves some combination of the words "digital editorial content strategy information design storytelling." You enjoy correct, well-organized information that's entertaining to navigate. You'd prefer not to build for virality, but instead create content that's long-lasting and influential.
The preferred infrastructure of the AI era will be in flux for years. But some tools and terms have emerged to support the little information cities we're building (for whatever reason). If you're building content to be read by people, crawlers, or agents, the next few weeks of The Content Technologist will cover concepts to build better in our new weird, wild, digital epistemology.
Series entries so far


Future entries of the series will include digressions on:
- Schema
- Reinforcement learning
- Knowledge graphs
- Retrieval augmented generation (RAG)
- Model context protocol (MCP)
- LLMs vs other AI models
- Ontology and taxonomy
In each issue, I'll outline my understanding of each concept to the best of my abilities. Whether you're jaded or enthused by AI, I hope understanding how these systems work helps us all survive the hype, sift through what's good, and create better content.
Establishing structure—for clients, for users, for audiences, for stakeholders, for this newsletter's editorial schedule—keeps our information systems prepared for complexity and unpredictability. Perhaps it's because my entire worldview and education is downstream from Jane Jacobs, Sesame Street, and The More You Know, but building media and information systems is only going to get more confusing from here. We might as well have a common vocabulary and understanding of how different elements of AI systems work, practically.
And if you enjoy this series, please share with friends and colleagues.
